Primeiras Impressões Quarkus Framework
28 APRIL 2020O ecossistema Java, desde o release do Java 8, vem numa crescente absurda de renovação. A prova disso é o surgimento de novos projetos, especificações e versões da linguagem em uma velocidade nunca antes vista.
Um dos projetos interessantes é o Eclipse MicroProfile, um projeto da Eclipse Foundation com a proposta de desenvolver um conjunto de especificações para a implementação de aplicações Cloud Native e Microserviços, dando uma roupagem atual ao desenvolvimento de aplicações web com Java.
O JavaEE renovando na velocidade da luz.
Mas podemos deixar para outro momento uma postagem específica sobre o projeto MicroProfile, nesse post vou tentar deixar as minhas impressões de um outro projeto muito interessante da RedHat, o framework Quarkus.
![]()
Quarkus Framework
No próprio site do Quarkus ele descrito como:
SUPERSONIC SUBATOMIC JAVA
A Kubernetes Native Java stack tailored for OpenJDK HotSpot and GraalVM, crafted from the best of breed Java libraries and standards.
A ideia do Quarkus é trazer um framework completamente pensado para aplicações Cloud Native, com a possibilidade de utilizar a GraalVM (código nativo executando super rápido e sem necessidade da gigantesca JVM).
Containers Java nunca mais terão aqueles 300mb do terror.
Diferente do Spring Boot, que tem um servidor de aplicação (por padrão Tomcat) embedded, o Quarkus utiliza o Netty como camada de tratamento de requisições HTTP. Outro paralelo com Spring Boot são as extensions do Quarkus, que se assemelham aos starters do Spring.
Além disso, no profile de desenvolvimento, o Quarkus tem uma poderosa função de de hot-reload que modifica a aplicação instantaneamente em tempo de execução ao editarmos o código.
Sem servidor sem deploy lento!
Como tem bastante coisa, vamos logo para o código!
Hands-on
Para testar o framework, fiz um projetinho bem simples de uma API.
Descrição
Basicamente quero adicionar minhas notas de corretagem, através da API, processar esses dados e exportar o resultado em forma de texto (para cada Ativo). Esse texto gerado será utilizado no campo descrição dos bens e direitos do Imposto de Renda e deve conter:
- Quantidade de total do Ativo
- O Ticket do Ativo (ex: PETR4)
- A Razão Social da Empresa
- O preço médio de compra (que é obrigatório para declaração)
- E a informação de custódia daquelas ações (em qual corretora elas estão custodiadas)
Criando o Projeto
O primeiro passo, depois de fazer o Hello World do framework, é acessar o link https://code.quarkus.io/. Nesse link tem uma ferramenta, estilo Spring Initializr, para a criação dos projetos e seleção de extensions que são integrações com outras bibliotecas (basicamente os starters do Spring).
As extensions que utilizei inicialmente foram:
- RESTEasy Jackson
- Hibernate Validator
- REST Client
- Hibernate ORM with Panache (Não conhecia o Panache, dei uma lida rápida e resolvi utilizar, acho que foi saudade de Ruby on Rails e o Active Record)
- JDBC Driver - PostgreSQL (Escolhi o Postgres apenas porque tenho utilizado esse banco em outros projetos, até podia utilizar H2, mas fui de elefantinho)
Basicamente foram essas. Tem muita coisa legal para testar, mas como o objetivo foi ter uma visão inicial do framework, vai ficar para a próxima. Quero muito testar as libs para cloud e umas integrações com o próprio Spring, quem sabe pode ser assunto de novas postagens.
Estrutura do Projeto
A estrutura do projeto é bem padrão. Um detalhe interessante é a pasta docker que já possui 2 Dockerfiles definidos; Um utilizando a JVM e outro a versão nativa (sem necessidade de JVM).
Como se trata de um framework da RedHat, as aplicações vem configuradas para utilizar uma imagem base do RedHat 8.1 (ubi-minimal:8.1).
Além disso, também já são criados:
- um endpoint base
- uma classe de teste utilizando JUnit 5 e RestAssured
- um arquivo estático index.html.
Endpoint Rest
Os endpoints REST seguem a especificação do JAX-RS.
Particularmente, prefiro as annotations do JAX-RS em relação às do Spring, acho algumas annotations do Spring meio confusas comparando com as do JAX-RS.
| JAX-RS | Spring | |
|---|---|---|
| @Path | @RequestMapping | |
| @GET | @GetMapping | |
| @POST | @PostMapping | |
| @PathParam | @PathVariable | |
| @QueryParam | @RequestParam |
Mas como diria uma amiga numa revisão de código…
“Por que tu não fez este como no de baixo? Achei mais organizado ou é peitica minha? @_@”
O código base é bem simples, e se você já utiliza Spring não terá problemas (exceto a peitica das annotations).
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Path("/hello")
public class ExampleResource {
@GET
@Produces(MediaType.TEXT_PLAIN)
public String hello() {
return "hello";
}
}
Data
O Quarkus possui diversas extensions para acesso a bancos de dados, inclusive com opções de bibliotecas reativas.
Algumas ainda estão com status de preview, mas os principais drivers JDBC estão estáveis.
Para configurar o acesso ao postgres, basta adicionar essas propriedades no arquivo application.properties.
#Database prorperties
quarkus.datasource.db-kind = postgresql
quarkus.datasource.username = postgres
quarkus.datasource.password = admin
quarkus.datasource.jdbc.url = jdbc:postgresql://localhost:5432/quarkus-test
# drop and create the database at startup (use `update` to only update the schema)
quarkus.hibernate-orm.database.generation=update
Panache
Como tinha dito, acho que fiquei com saudade do Rails e o Active Record. Quando estava lendo as possíveis extensions me deparei com o Panache e a possibilidade de utilizar, sem muito esforço de configuração, o padrão Active Record Para acesso e manipulação das entidades do banco.
Basta que a classe de Entidade estenda PanacheEntity e já ganhamos de ‘brinde’ a geração do Id e o Active Record.
import javax.persistence.Entity;
import javax.persistence.EnumType;
import javax.persistence.Enumerated;
import javax.persistence.Table;
import javax.persistence.UniqueConstraint;
import javax.validation.constraints.NotBlank;
import org.hibernate.validator.constraints.br.CNPJ;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
@Entity
@Table(uniqueConstraints = @UniqueConstraint(columnNames = { "ticket" }))
public class Ativo extends PanacheEntity {
@CNPJ
private String cnpj;
@NotBlank
private String razaoSocial;
@NotBlank
private String ticket;
@Enumerated(EnumType.STRING)
private Tipo tipo;
protected Ativo() {
}
public Ativo(@CNPJ String cnpj, @NotBlank String razaoSocial, @NotBlank String ticket, Tipo tipo) {
this.cnpj = cnpj;
this.razaoSocial = razaoSocial;
this.ticket = ticket;
this.tipo = tipo;
}
public String ticket() {
return this.ticket;
}
public String tipo() {
return this.tipo.name();
}
}
Assim, já é possível mandar aquele persist da própria classe de entidade.
Detalhe para a um ponto, é necessário que a entidade esteja dentro de um contexto transacional se a operação envolver mudanças no banco.
Make sure to wrap methods modifying your database (e.g. entity.persist()) within a transaction. Marking a CDI bean method @Transactional will do that for you and make that method a transaction boundary. We recommend doing so at your application entry point boundaries like your REST endpoint controllers.
import javax.transaction.Transactional;
import javax.validation.Valid;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Path("/ativos")
public class AtivoController {
@Transactional
@POST
@Produces(MediaType.APPLICATION_JSON)
public Ativo cadastrarAtivo(@Valid NovoAtivoDTO request) {
Ativo novoAtivo = request.toEntity();
novoAtivo.persist();
return novoAtivo;
}
}
O Panache é uma alternativa bem interessante ao Spring Data JPA, já que, além de implementar o padrão Active Record, também permite utilizar o padrão Repository.
@ApplicationScoped
public class PersonRepository implements PanacheRepository<Person> {
// put your custom logic here as instance methods
public Person findByName(String name){
return find("name", name).firstResult();
}
public List<Person> findAlive(){
return list("status", Status.Alive);
}
public void deleteStefs(){
delete("name", "Stef");
}
}
Uma diferença do Spring Data JPA na criação de repositórios é que no Panache devemos implementar a interface ***PanacheRepository
Rest Client
Outra extension bem legal, que adicionei assim que ‘bati o olho’, é a especificação de Rest Client do MicroProfile.
Pra quem já estudou ou trabalhou com Spring Cloud, vai lembrar do projeto Feign.
A proposta é implementar clientes HTTP de forma declarativa. Basta declarar uma interface, anota-la com @RegisterRestClient, montar o @Path de acesso ao serviço, declalar o verbo HTTP utilizado e voilà, cliente Rest funcionando.
Aqui adicionei uma configKey, que pode ser definida no arquivo de propriedades com a BaseURI do serviço.
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import org.eclipse.microprofile.rest.client.inject.RegisterRestClient;
@Path("/cnpj")
@RegisterRestClient(configKey = "receita-service")
public interface ReceitaService {
@GET
@Path("/{cnpj}")
Optional<ReceitaResponseModel> getByCnpj(@PathParam("cnpj") String cnpj);
}
application.properties
#Rest Client
receita-service/mp-rest/url=https://my-service/v1
Executando a Aplicação
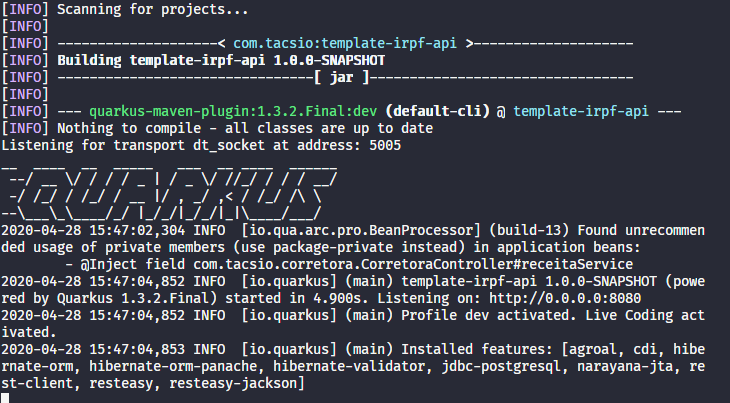
Para executar a aplicação basta rodar o comando maven abaixo e se impressionar com o tempo de startup.
./mvnw compile quarkus:dev
Considerações Finais
Confesso que ficou muito rasteira essas primeiras impressões, pelas possibilidades do framework ainda há muito que explorar. Se você já conhece o Spring provavelmente vai se perguntar “Por que eu mudaria para o Quarkus?” Fiz essa mesma pergunta e resolvi testar (recomendo o teste), acho que ao adentrar nas extensions para cloud vou entender melhor as diferenças e semelhanças entre os frameworks e quem sabe até me sentir mais capacitado para fazer esse tipo escolha (afinal cada caso é um caso).
Surpresas
Me surpreendi bastante com o tempo de startup da aplicação. O fato dos runtimes MicroProfile utilizarem apenas a camada HTTP e não todo o servidor de aplicação faz um diferença absurda.
Outro ponto muito bom, também relacionado a velocidade, é o quão rápido é feito o hot-reload da aplicação quando uma mudança no código é realizada, está nível nodemon para quem desenvolve com NodeJS.
Código Fonte
O código fonte está disponível no Github. Ainda não tem muita coisa, mas já é um começo!
Referências
MicroProfile: https://projects.eclipse.org/projects/technology.microprofile
Quarkus Framework: https://quarkus.io/
Panache: https://quarkus.io/guides/hibernate-orm-panache
Active Record Pattern: https://en.wikipedia.org/wiki/Active_record_pattern
Spring Data JPA: https://spring.io/projects/spring-data-jpa
MicroProfile Rest Client: https://github.com/eclipse/microprofile-rest-client
Spring Cloud: https://spring.io/projects/spring-cloud